
No, I Don't Believe That Your Drug Was "200% Better" Than Placebo
No, I Don't Believe That Your Drug Was "200% Better" Than Placebo
Stop Using Relative Change on Differential Outcome Measures

It can sometimes feel like the more I learn about Alzheimer’s clinical trials the more intense my headache. The context this week is provided by yet another misleading characterization of a failed clinical trial extension—Cassava Sciences’ Cognition Maintenance Study—combined with some closely related concerns that I have about how Eisai characterized their otherwise successful (in a pretty strongly qualified sense) Leqembi trial, something that I had not recognized until the FDA approval of Leqembi resurfaced some prior criticism. So, to that end, I’d like to talk a bit about percentage difference (or, as it is often called, relative change).
Let’s start with Leqembi, née lecanemab, which was recently approved for certain indications of Alzheimer’s disease, having shown statistically significant treatment effect in a large Phase 3 trial. Most of the hubbub around the drug has focused on the relative benefit (is the drug “disease modifying?” probably not) versus the risk of a potentially serious side effect called ARIA. These are perfectly reasonable things to dwell on. The risk is quite serious for a benefit that appears very small, but whether or not that should preclude approval of an apparently legitimate treatment effect for a disease with no real long term medications is not something I feel that I can comment strongly about one way or another given my current level of familiarity with the drug. However, part of the benefit that was sold wholesale to onlookers was a 27% slowing in the rate of decline measured on the primary outcome metric, CDR-SB. This number was subsequently paraded around within institutions like The Lancet and the NIH NIA, becoming the headline of the sales pitch for Leqembi’s approval. It is, unfortunately, a problematic number.
The issue with the oft-cited 27% slowing in cognitive decline was noted by astute observers at the time—Matthew Schrag, an Alzheimer’s researcher who has emerged as a keen-eyed watchdog over the last couple years, pointed out that the 27% was a relative measure, and that the absolute reduction in decline was 2.5%, a pretty marked difference. So which number should we take more seriously? Definitely not the 27%, it turns out. But why not? To answer that question we have to look a little more closely at what we’re trying to measure.
Alzheimer’s therapy development is, unfortunately, a necessarily pessimistic field. We’ve never seen a drug come anywhere close to stopping—let alone reversing—the progression of the disease, so recent clinical trials mostly hinge on just slowing it down. Slowing the disease is meaningful, of course, but it means that we have to wrestle with a sometimes barely perceptible change in the slope of two lines. Those lines will unflinchingly trend downwards, but the treatment line might trend a bit slower. See the following figure, which shows the relative change from baseline for lecanemab and placebo over the course of 18 months:

Lecanemab is better! But how much better? It’s natural to want to express the difference as a percentage. So what Eisai apparently did was take the the last two points along the line and calculate the percentage difference between them. According to the publication, those two numbers were 1.21 for lecanemab and 1.66 for placebo, and (1.66 - 1.21)/1.66 = 0.271, or 27.1%. Folks, do not do this. And if you see a pharmaceutical company (or a journal, or the NIH) do this, ask them to justify it, and perhaps suggest that they stop.
The reason that we absolutely do not want to do this stems from the outcome measure being a difference—in “mathy” terms, there was a rescaling that removed information about the absolute difference, which seriously inflates the difference of the new quantities. But it’s much worse, because this rescaling pivots us around zero. The problem is not so obvious when both lines start going down right away, but what if one (or both) didn’t? One trick that gets drilled into you while studying physics is to always be testing limits. If your equation blows up unexpectedly at the limits then it’s a sign that something is almost certainly very wrong with it. Usually, the limits that reveal the most are zero and infinity. So, what would our outcome measure look like if the treatment stabilized at zero change? It would mean 100% difference. Ok, makes sense, but what about if the treatment group actually improved somewhat? You’d get, maybe, 110% difference! A bit weird, but sort of works. How about if the placebo stabilized at zero while the treatment group improved a little? That’s, er, infinite difference? What about if they both stabilized? Undefined difference? Can we use L'Hôpital's rule?
These failed and strange difference tests might sound academic, but they show us something important about the outcome metric—namely, that it doesn’t work. It only looks like it works because we’re used to seeing every Alzheimer’s disease trial contain two downward sloping lines that start at zero. Even then, best case is it inflates the difference. But now let’s look at the effect this has on less, uh, rigorous trial analyses.
Cassava Sciences, with whom readers are no doubt familiar, published results from their CMS study with the headline that stated the drug “slowed cognitive decline” for the group that continued treatment versus the one that withdrew. The analysis was provided by a biostatistics consulting firm, Pentara Corporation, who have thus far declined to comment about any aspect of their pair of trial analyses for Cassava. In this new analysis, two datasets are presented, both of which clearly state about the primary outcome measures that they were “not significant for sample sizes.” So, the trial was a failure, correct? Well, what does the percentage difference have to say about it?
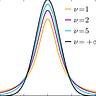
For these two datasets that showed no statistically significant difference, the percentage difference between the placebo and treatment was 38% and 205%. Wow! Home run, right? Setting aside for a moment that the error bars are enormous (oh, and unreported), what does this 205% difference actually look like? See below:

Can you spot what’s going on here? It’s the zero-limit failure mode. Thanks to Eisai et al. there is credence to the idea that percentage difference is a legitimate outcome measure here. It isn’t. Allow me show you what happens when you start taking percentage differences around zero:

Because I get to put one of the data points in the denominator, any pair of points that is symmetric around zero will naturally produce 200% difference. You could take the absolute difference to the limit of zero and still come up with 200% relative difference. Or, in simple math terms, if y = -x, then (y - x)/x = (-2x)/x = -2, regardless of our choice of x and y or the difference between them. Treatment improves by 10 points and placebo declines by 10? 200% different. Treatment improves by 0.1 points and placebo declines by 0.1? 200% different.
Clearly, this makes no sense, and we shouldn’t be giving clinical trial sponsors a free pass on reporting it.
I agree strongly with your overall point. However, I have to wonder if this sentence:
"Cassava Sciences, with whom readers are no doubt familiar, published results from their CMS study with the headline that stated the drug “slowed cognitive decline” for the group that withdrew from treatment versus the one that continued."
is really the right way around: Cassava is claiming that the drug had a benefit for the group that withdrew from treatment with the drug, and not the group that continued to take it?
yes, the percentages meann nothing but a cognitive gain for the drug arm vs degradation in the placebo is very significant and not shown in the approval recently granted